Prometheus 개념 및 동작 원리 / 아키텍처 분석
Prometheus란?
- Prometheus는 SoundCloud사에서 만든 오픈소스 모니터링 툴이다.
- 메트릭 이름과 Key-Value 쌍으로 식별되는 시계열 데이터가 있는 다차원 데이터 모델
- 시스템 모니터링 및 경고 툴킷으로 kubernetes에서도 Prometheus를 사용하여 모니터링하는 방식을 장려하고 있다.
- 하지만 시각화 도구가 부족해서 Grafana를 이용하여 시각화하는 방식을 많이 사용한다.
메트릭이란?
비즈니스 측정치와 핵심 실적 지표를 나타내는 것. 데이터를 시각화해서 우리들에게 보여주는 툴.
예를 들어 대시보드에서 CPU사용량, 시간당 데이터 처리량 등을 볼 수 있는 것과 같다.
동작 원리는 다음과 같다.

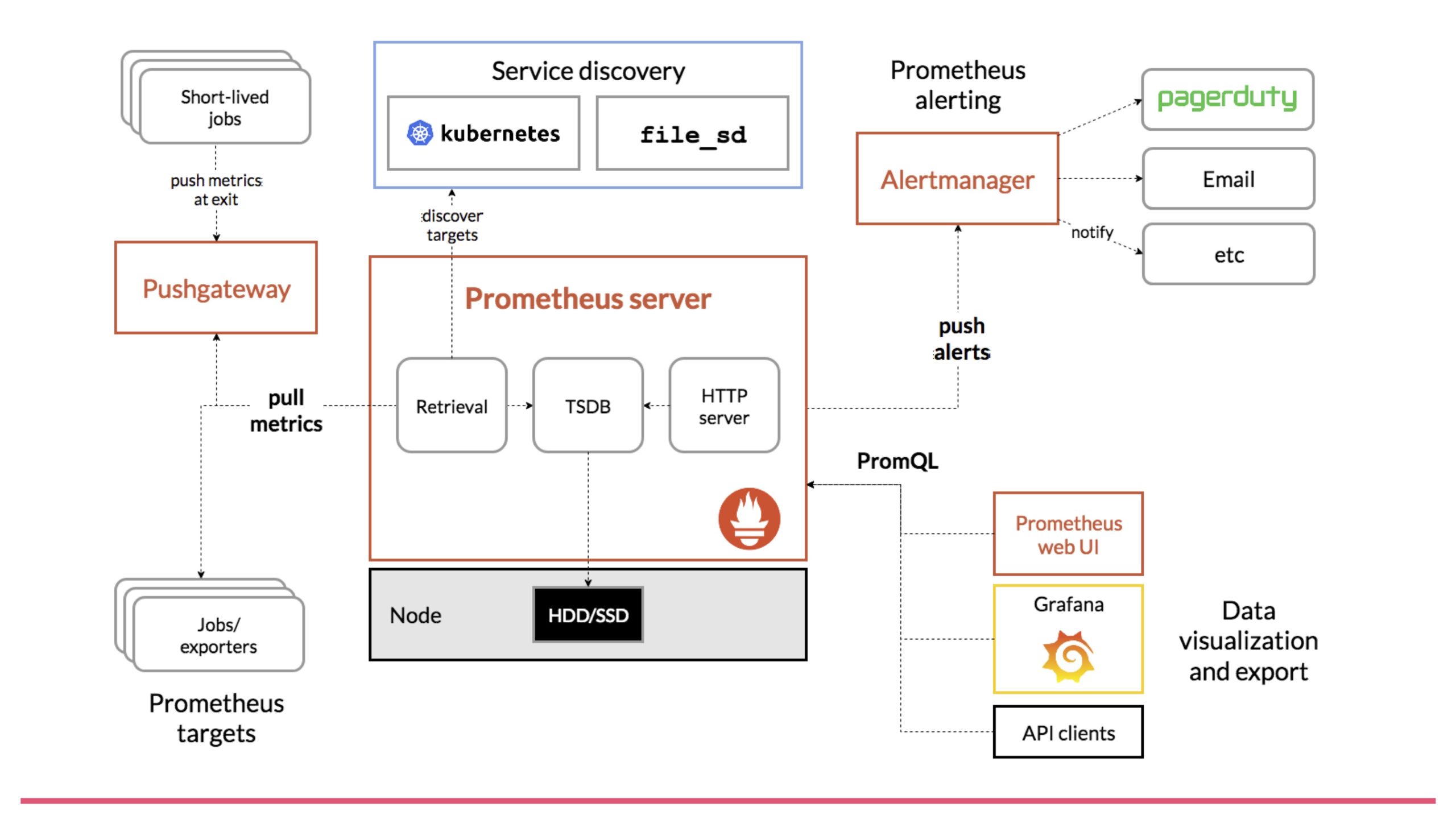
1. metric 수집
수집하려는 대상 시스템(Target System)에서 메트릭 정보를 수집한다. 이 대상 시스템에서 메트릭을 프로메테우스로 전송하기 위해서 Exporter라는 것을 사용한다.
2. Pulling
프로메테우스는 Target System에서 메트릭 정보를 수집할 때 Pull 방식을 사용한다.
모니터링 시스템은 대체로 에이전트가 모니터링 시스템으로 메트릭을 보내는 Push 방식을 사용한다.
하지만 프로메테우스는 주기적으로 Exporter로부터 메트릭을 읽어와서 수집하는 방식이다.
Push 방식은 서비스가 오토 스케일링 등으로 가변적일 경우에 유리하다.
Pull 방식은 모니터링 대상이 가변적으로 변경될 경우, 모니터링 대상의 IP 주소를 알 수 없기 때문에 어려운 점이 있다. 이러한 문제를 해결하기 위한 방안이 서비스 디스커버리라는 방식인데, 특정 시스템이 현재 기동 중인 서비스들의 목록과 IP 주소를 가지고 있으면 된다.
3. Exporter
모니터링 에이전트로써 Target System에서 메트릭을 읽고 프로메테우스가 Pulling 할 수 있도록 한다. 또한 HTTP GET으로 메트릭을 텍스트 형태로 프로메테우스에 리턴한다.
4. Retrieval
서비스 디스커버리 시스템으로부터 모니터링 대상 목록을 받아오고, Exporter로부터 주기적으로 메트릭을 수집하는 모듈이다.
5. 저장
이렇게 수집된 정보는 프로메테우스 내의 메모리와 로컬 디스크에 저장된다. 별도의 데이터 베이스 등을 사용하지 않고, 그냥 로컬 디스크에 저장하는데, 그로 인해 설치가 매우 쉽다는 장점이 있는 반면에 스케일링이 불가능하다는 단점을 가지고 있다. 대상 시스템이 늘어날수록 메트릭 저장 공간이 많이 필요한데, 단순히 디스크를 늘리는 방법 밖에 없다.
프로메테우스는 구조상 이중화나 클러스터링 등이 불가능하다.
6. 서빙
이렇게 저장된 메트릭은 PromQA 쿼리 언어를 이용해서 조회가 가능하고, 이를 외부 API나 프로메테우스 웹콘솔을 이용해서 서빙이 가능하다. 또한 그라파나 등과 통합하여 대시보드 등을 구성하는 것이 가능하다.
장단점
장점
- pull 방식으 구조로, 모든 메트릭의 정보를 중앙 서버로 보내지 않아도 된다.
- 대부분의 모니터링 구조는 push 방식인데, 각 타깃 서버에서 부하가 걸릴 경우 push 방식은 fail point가 될 가능성이 있다.
- Kubernetes 환경에서 설치가 간단하고 Grafana와 연동 시 운영이 쉽다.
- Linux, Window 등의 OS metric 뿐 아니라 각종 Third-party의 export를 제공한다.
- 데이터 저장소가 시계열 데이터 저장소로 구성되어 있어, 많은 양의 정보를 빠르게 검색 가능하다.
단점
- 싱글 호스트 아키텍처이다. 따라서 확장이 불가능하고, 저장 용량이 부족하면 디스크 용량을 늘리는 방법 밖에 없다.
- 일정 pulling 주기를 기반으로 metrics를 가져오기 때문에 pulling 하는 순간의 스냅샷 정보만 알 수 있다.
- 프로메테우스 서버가 다운되거나, 재시작을 할 경우 metrics가 유실된다.
아키텍처 분석
1. 프로메테우스의 스토리지 기본 구조
프로메테우스는 기본적으로 TSDB(Time Series Database)를 사용한다.
2. 프로메테우스의 데이터는 어떻게 저장되는가?
프로메테우스가 데이터를 저장하는 방식은 두 가지가 있다.
- 로컬 파일 시스템: 일반적인 chunk 블록 파일
- 인메모리: WAL(Write Ahead Logging) 파일 & 인메모리 버퍼
InfluxDB 같은 DB와는 달리 프로메테우스는 레코드를 수집하고 나서 해당 레코드 데이터를 즉시 스토리지에 저장하지 않는다.
일단 들어온 데이터를 인메모리 버퍼에 잔뜩 들고 있다가,
새로 들어온 레코드가 현재 메모리 페이지의 크기를 32KB가 넘어가게 만드는 경우 현재 페이지를 WAL 파일에 Flush 한다.
이렇게 저장되는 데이터 공간을 Head Block이라고 부른다.
Head Block의 데이터가 백업되는 WAL 파일은 최대 128MB를 차지할 수 있으며, 128MB가 넘을 경우에 새로운 WAL 파일이 생성된다. 이 WAL 파일은 인메모리 데이터의 손실을 방지하기 위한 것으로, 프로메테우스가 비정상적으로 종료되는 crash가 발생할 경우 현재 존재하는 WAL를 다시 읽어들여 원래의 데이터를 복구하는 replay 작업을 수행한다.
이 때, WAL 파일을 다시 읽어들이는 기준점은 wal 디렉토리에 존재하는 checkpoint.XXXX가 된다.
참고로 네트워크 스토리지를 쓰게 되면 checkpoint나 WAL 파일이 깨지는 corruption이 발생할 수도 있는데, 이 경우에 프로메테우스의 재시작이 계속해서 실패할 수도 있고, 새로운 chunk 블록이 생성되지 않아서 이상하게 꼬여버릴 수도 있다. 이런 경우에는 어쩔 수 없이 데이터를 삭제해야만 하니 로컬 스토리지를 쓰는 것이 안정성 면에서 현명한 선택일 수 있다.
3. chunk 블록의 병합과 meta.json
프로메테우스는 데이터를 인메모리와 WAL에 저장하고 있다가, 주기적으로 데이터를 chunk 블록으로 flush 한 뒤 가장 오래된 WAL 파일을 삭제한다.01HLY... 처럼 이상한 문자열로 이루어진 디렉토리가 chunk 블록에 해당하는데, 이 디렉토리에는 특정 Time Window의 레코드가 inverted index 파일과 함께 저장되어 있다.
프로메테우스에서 쿼리를 할 때는 이러한 여러 개의 chunk 블록에 대해 레코드 색인을 한 뒤, 결과를 하나로 합쳐서 사용자에게 보여준다. index 파일이 존재하기 때문에 전수 검사는 발생하지 않으며, 각 index 파일과 블록 데이터는 필요에 따라 mmap을 통해 메모리에 올라가게 된다.
재미있는 점은 시간이 흐를 수록 이 블록들이 계속해서 늘어나는 것이 아니라는 점이다.
프로메테우스의 옵션에 따라 블록이 합쳐질 수도 이고, retention에 따라 삭제될 수도 있다.
관련 옵션은 아래 두 가지가 있다.
--storage.tsdb.min-block-duration: 하나의 블록에 저장될 데이터의 time window를 뜻한다. 예를 들어 이 옵션의 값이 2h일 경우, 하나의 chunk 블록 디렉토리에는 2시간 동안의 데이터가 들어가 있다.
--storage.tsdb.max-bolck-duration: 하나의 블록에 최대로 저장할 수 있는 time window를 뜻한다. 예를 들어 이 옵션의 값이 12h일 경우, 하나의 chunk 블록 디렉토리에는 최대 12시간 만큼의 데이터를 보관할 수 있다. 기본 값은 블록의 retention을 설정하는 옵션인 --storage.tsdb.retention.time의 10%로 설정된다.
4. 데이터 삭제와 tombstone 파일
각 chunk 블록에는 tombstone 이라는 파일이 존재하는데, 이는 말 그대로 데이터의 비석 역할을 한다. 프로메테우스 API를 통해 특정 조건에 해당하는 데이터를 삭제할 경우, 비석에 "이 조건에 해당하는 데이터는 죽었다"하고 기록만 해 놓을 뿐 즉시 삭제하지는 않는다. 실제로 데이터가 삭제되는 시점은 주기적으로 프로메테우스가 블록을 갱신할 때이지만, clean tombstone API를 통해 즉시 데이터를 날리는 것도 가능하다.
POST/api/v1/admin/clean_tombstones
PUT/api/v1/admin/tsdb/clean_tombstones
5. 프로메테우스의 capacity 결정하기
프로메테우스를 프로비저닝 할 때 가장 중요한 것은 메모리와 스토리지 용량을 얼마나 줄 것인지를 결정하는 일인데, 당연히 처음에는 정확한 용량을 가늠하기 어렵다. 각 데이터 샘플의 크기나 scrape 개수, 라벨 카디널리티가 얼마나 되는지를 대략적으로라도 알아야 이를 계산할수 있기 때문이다. 프로메테우스 config에서만 target을 제어할 수 있으면 참 좋겠지만 쿠버네티스에서는 annotation을 통해서도 scrape를 할 수 있기 때문에 scrape 개수를 한 눈에 파악하기는 어렵다.
프로메테우스는 mmap으로 chunk 블록 데이터를 읽어올 뿐만 아니라, Head Bock 데이터까지 메모리에 항상 상주해있으니 웬만하면 메모리는 크게 잡아주는 것이 좋다. 만약 메모리를 너무 많이 차지해서 OOM(Out of Memory)이 발생한다면 hashmode로 샤딩을 고려해볼 수 있다.
6. 트리비아
프로메테우스는 자체적으로 /metrics 엔드포인트를 제공하고 있으며, 이 엔드포인트에서 수집되는 데이터들은 프로메테우스가 잘 동작하고 있는지를 나타내는 중요한 지표가 될 수 있다.
예를 들어 블록의 생성/삭제 등과 같은 지표들도 전부 가져올 수 있다. 이해하고 나면 거의 대부분 소중한 메트릭들이니, 꼭 grafana에서 시각화하도록 하자.
참고 사이트: 191. [Prometheus] 프로메테우스 스토리지 아키텍처 간단 분석 : 네이버 블로그 (naver.com)